개요
MySQL 의 복제 기능은 소위 "스케일 아웃"이라는 아키텍처를 사용하는 고성능 애플리케이션의 기반이 된다. 복제를 통해 하나 이상의 서버를 다른 서버의 레플리카로 구성하여 데이터를 소스 복사본과 동기화할 수 있다. 이는 고성능 애플리케이션에 유용할 뿐만 아니라 고가용성, 확장성, 재해 복구, 백업, 분석, 데이터 웨어하우징 등 여러 작업을 위한 초석이 되기도 한다.
복제는 대략적인 과정은 다음과 같다. 소스 서버의 로그에 데이터 또는 데이터 구조를 수정하는 이벤트를 기록한다. 그러면 레플리카 서버는 소스의 로그에서 이벤트를 읽고 재생할 수 있다. 당연히 이렇게 되면 실시간과 레플리카에 표시된 시간 사이의 지연 ( 레플리카 지연 )이 발생하고, 이는 쿼리의 규모에 따라 몇 초, 몇 분 또는 몇 시간 늦어질 수 있다.
MySQL의 복제는 대부분 이전 버전과 호환된다. 즉, 최신 서버는 일반적으로 문제 없이 이전 서버의 레플리카가 될 수 있다. 하지만 반대로 이전 버전의 서버는 새 버전의 레플리카로 작동할 수 없는 경우가 많다. 가령, 새 서버에서 사용하는 신규 기능이나 구문을 이해하지 못할 수 있고, 복제에 사용되는 파일 형식이 다를 수도 있다. 따라서 메이너 버전과 마이너 버전이 달라지는 업그레이드를 진행하는 경우에 이를 유의해야한다.
복제는 레플리카에 지정할 수 있는 읽기 확장에 비교적 적합하지만 올바르게 설계하지 않으면 쓰기를 확장하는 좋은 방법이 되지 못한다. 많은 레플리카를 소스에 연결하면 각 레플리카에서 한 번씩 쓰기가 여러 번 수행된다.
복제에 대한 일반적인 사용법
데이터 분산
MySQL의 복제는 일반적으로 대역폭을 많이 사용하지 않지만, 행 기반 복제는 기존의 명령문 기반 복제보다 훨씬 더 많은 대역폭을 사용할 수 있다. 복제를 마음대로 중지하고 시작할 수도 있다. 따라서 다른 데이터 센터나 클라우드 영역과 같이 지리적으로 멀리 떨어진 위치에 데이터 복사본을 유지하는 데 유용하다.
읽기 트래픽 확장
MySQL 복제는 읽기 쿼리를 여러 서버에 분산시키는 데 도움이 되며, 특히 읽기 집약적인 애플리케이션에 매우 적합하다. typeorm과 같은 ORM 라이브러리를 통해 코드 몇 줄만 추가하면 기본적인 로드 밸런싱도 수행할 수 있다.
백업
복제는 백업을 돕는 유용한 기술이다. 다만, 레플리카는 백업이 아니며, 백업을 대체할 수도 없다.
분석 및 보고
보고/분석 쿼리를 위해 전용 레플리카를 사용하는 것은 비즈니스에 영향을 주지 않는 좋은 전략이다.
고가용성 및 장애 조치
복제는 MySQL이 애플리케이션에서 단일 장애 지점이 되는 것을 방지할 수 있다. 복제와 관련된 우수한 장애 조치 시스템을 사용하면 다운타임을 크게 줄일 수 있다.
MySQL 업그레이드 테스트
모든 인스턴스를 업그레이드하기 전, 업그레이드된 버전을 레플리카로 설정하고 쿼리가 정상 작동하는지 확인하는 것이 일반적이다.
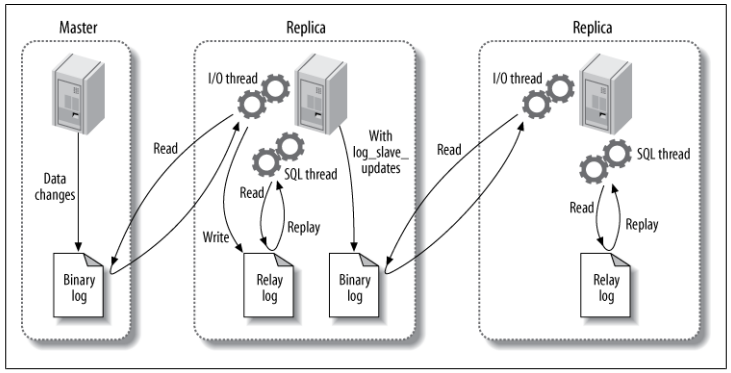
복제 작동 방식
대체로 복제는 간단한 3단계 프로세스이다.
1. 소스는 데이터의 변경 사항을 바이너리 로그에 "바이너리 로그 이벤트"로 기록한다.
2. 레플리카는 소스의 바이너리 로그 이벤트를 자체 로컬 릴레이 로그에 복사한다.
3. 레플리카는 릴레이 로그의 이벤트를 재생하여 자체 데이터에 변경 사항을 적용한다.

복제의 내부 동작
복제 형식 선택
MySQL은 복제를 위해 명령문 기반, 행 기반, 혼합의 세 가지 바이너리 로그 형식을 제공한다. 이는 binlog_format 설정 변수를 통해 제어 가능하다.
- 명령문 기반
명령문 기반 복제는 소스에서 데이터를 변경한 쿼리를 기록하여 작동한다. 레플리카가 릴레이 로그에서 이벤트를 읽고 실행할 때, 소스가 실행한 실제 SQL 쿼리를 다시 실행한다. 이것의 장점은 간단하고 컴팩트하다는 것이다. 대량의 데이터를 업데이트하더라도 바이너리 로그는 수십 바이트만 쌓인다. 반면, 가장 큰 단점은 비결정적 쿼리를 실행할 때 나타난다. 가령, ORDER BY 절이 없는 1,000행의 테이블의 100행을 제거하는 쿼리가 실행된다면, 소스와 레플리카 간 행 순서가 다를 경우 데이터 불일치가 발생할 수 있다.
- 행 기반
행 기반 복제는 행이 어떻게 변경되었는지 나타내는 이벤트를 바이너리 로그에 기록한다. 행 기반에서는 바이너리 로그를 보고 정확히 어떤 행이 어떻게 바뀌었는지 확인할 수 있다. 그렇기에 비결정적 쿼리의 영향을 받지 않는다. 이것의 단점은 영향 받은 모든 행에 대해 행 데이터 변경에 대한 이벤트를 작성하면 바이너리 로그가 크게 증가할 수 있다.
- 혼합
혼합 방식은 명령문 기반 형식을 기본값으로 사용하고, 필요할 때만 행 기반 형식으로 전환하여 위 두 가지 방식의 장점을 결합시키고자 시도한다. '시도'인 이유는 각 항목을 언제 쓸지에 대해 충족해야 하는 많은 조건이 있고 이로 인해 바이너리 로그에 예측할 수 없는 이벤트가 발생하기 때문에 이것 저것 해보아야 하기 때문이다.
전역 트랜잭션 식별자
MySQL 5.6 버전까지 레플리카는 소스에 연결할 때 읽고 있던 바이너리 로그 파일과 로그 위치를 추적해야 했다. 레플리카는 바이너리 로그의 이벤트를 읽을 때마다 위치를 이동한다. 만약 이 때 재해가 발생하여 소스가 손상되어 백업에서 데이터를 다시 작성해야하는 상황이 발생했다고 가정해보자. 바이너리 로그가 다시 시작되었다면 레플리카를 어떻게 다시 연결할 수 있을까? 다시 연결하는 과정은 상당히 복잡한 프로세스가 된다. 실수로 너무 일찍 이동하면 이벤트가 중복될 수 있고, 너무 늦으면 이벤트를 건너뛸 수 있다.
이 문제를 해결하기 위해 MySQL은 복제 위치를 추적하는 대체 방법인 GTID( 전역 트랜잭션 식별자 )를 추가하였다. GTID를 사용하면 소스 서버가 커밋하는 모든 트랜잭션에 고유 식별자가 할당된다. 트랜잭션이 바이너리 로그에 기록되면 GTID도 함께 기록된다. SQL 스레드는 트랜잭션을 커밋할 때 GTID도 완료된 것으로 기록한다.
GTID는 MySQL 복제를 실행할 때 가장 골치 아픈 부분 중 하나인 로그 파일과 위치로 처리하던 부분을 해결한다. 공식 MySQL 문서의 안내대로 항상 데이터베이스에 대해 GTID를 활성화하는 것이 좋다.
복제 충돌의 대비
GTID를 통해 로그 파일과 위치 문제를 해결했지만, 여전히 복제가 중단될 여지는 남아있다. 복제의 중단을 방지하기 위해 아래와 같은 설정을 할 것을 권장한다.
innodb_flush_log_at_trx_commit = 1
이 설정을 통해 각 트랜잭션에서 로그를 기록하고 디스크에 동기화할 수 있다. 바이너리 로그이 벤트가 먼저 커밋된 다음 트랜잭션이 커밋되어 디스크로 플러시되기에 데이터를 잘 보호할 수 있다.
sync_binlog = 1
이 변수는 MySQL이 바이너리 로그 데이터를 디스크에 동기화하는 빈도를 제어한다. 1로 설정할 경우, 모든 트랜잭션 이전을 의미하며, 이는 서버 충돌 시 트랜잭션 손실을 방지한다.
relay_log_info_repository = TABLE
복제가 완료된 트랜잭션은 두 번째 단계로 디스크에 동기화해야 한다. 이 때, 트랜잭션 커밋과 동기화 사이에 충돌이 발생한 경우, 디스크의 파일에 잘못된 파일과 위치가 있을 수 있다. 이 설정은 MySQL 자체 내의 InnoDB 테이블로 옮겨져 레플리카에서 동일 트랜잭션 내의 트랜잭션과 릴레이 로그 정보를 모두 업데이트 할 수 있다.
relay_log_recovery = ON
이것은 충돌이 감지되면 모든 로컬 릴레이 로그를 제거하고 소스에서 누락된 데이터를 가져온다.
지연 복제
때로는 토폴로지에 지연된 레플리카가 있는 것이 유리할 수 있다. 지연 복제는 데이터를 온라인 상태로 유지하고 실행하면서도 몇 시간 또는 며칠씩 실시간보다 일관되게 늦출 수 있다. 이는 CHANGE REPLICATION SOURCE TO 문과 SOURCE DELAY 옵션으로 설정 가능하다.
만약 많은 양의 데이터로 작업 중인 상황에서 실수로 테이블 삭제 등의 작업 실수가 일어났다고 가정하자. 백업에서 복원하는 데에는 몇 시간이 소요될 수 있지만, 시간 지연 레플리카를 사용하면 DROP TABLE의 GTID를 찾아 해당 테이블이 삭제되기 직전까지 복제를 따라잡을 수 있다.
물론 이것은 운영 측면에서 복잡성을 초래한다. 지연 복제를 사용하기로 결정했다면 이 지연 레플리카를 소스 노드 후보에서 적절하게 제외하는 방법 ( HA 등이 적용되었다면 더우 중요 ), 복제를 모니터링하는 방법 등이 충분히 고려되어야 한다.
멀티 스레드 복제
복제의 과거 문제는 소스에서 병렬로 쓸 수 있는 반면 레플리카는 단일 스레드라는 것이었다. 최신 MySQL은 멀티 스레드 복제를 제공하여, 릴레이 로그 변경 사항을 로컬로 적용할 수 있다.
멀티 스레드 복제에는 DATABASE와 LOGICAL CLOCK 두 가지 모드가 있다.
DATABASE 옵션은 여러 스레드를 사용하여 서로 다른 데이터 베이스를 업데이트 한다. 반면, LOGICAL CLOCK은 동일한 바이너리 로그 그룹 커밋 단위로 동일 데이터베이스에 대한 병렬 업데이트를 수행한다.
반동기 복제
반동기식 복제를 활성화하면 소스가 커밋하는 모든 트랜잭션은 하나 이상의 레플리카에서 수신된 것으로 확인되어야 한다. 확인 방법은 레플리카가 커밋을 수신하고 자신의 릴레이 로그에서 성공적으로 기록했음을 확인하는 것이다.
각 트랜잭션은 다른 노드의 응답을 기다려야 하므로 이 기능은 서버가 수행하는 모든 트랜잭션에 대기 시간을 추가한다. 따라서 이에 대한 트레이드 오프를 적절히 고려해야 한다.
여기서 매우 중요한 점은 일정 기간 동안 트랜잭션을 승인하는 레플리카가 없으면 MySQL은 표준 비동기식 복제로 되돌아간다는 것이다. 이를 통해 반동기식 복제는 데이터 손실을 방지하는 도구라기보다는 탄력적인 Failover를 수행할 수 있게 하는 대규모 툴셋 구성요소라는 것을 알 수 있다.
'Database > High Performance MySQL' 카테고리의 다른 글
| MySQL 복제 (2) (0) | 2023.12.12 |
|---|---|
| 쿼리 성능 최적화 (2) (2) | 2023.11.30 |
| 쿼리 성능 최적화 (1) (0) | 2023.11.28 |
| 고성능을 위한 인덱싱 (2) (2) | 2023.11.09 |
| 고성능을 위한 인덱싱 (1) (0) | 2023.11.07 |