성능 스키마 사용
앞서서, 성능 스키마가 무엇인지, 이를 어떻게 설정하는지 알아보았다면, 이곳에서는 성능 스키마를 통해 일반적인 문제를 해결해보고자 한다.
SQL문 점검
1. Performance schema 직접 사용
성능 스키마는 SQL문의 성능을 점검하기 위해 다양한 인스트루먼트 세트를 제공한다. performance_schema를 사용하면 성능 문제를 일으키는 쿼리와 이유를 쉽게 찾을 수 있다.
아래와 같은 유형의 인스트루먼트를 활성화하면 SQL 구문 인스트루먼트를 확인할 수 있다.
| Instrument Class | Description |
| statement/sql | SELECT 또는 CREATE TABLE 과 같은 SQL문 |
| statement/sp | Stored Procedure 제어 |
| statement/scheduler | Event Scheduler |
| statement/com | quit, KILL, DROP DATABASE, Binlog Dump와 같은 명령어. 몇몇은 사용자가 사용할 수 없으며 mysqld 프로세스 자체에 의해 호출됨 |
| statement/abstract | 네 가지 명령 클래스 ( clone, Query, new_packet, relay_log ) |
성능 스키마는 events_statements_current, events_statements_history, events_statements_history_long 테이블에 구문 메트릭스를 저장한다. 세 테이블 모두 동일한 구조를 갖고 있다. 세 테이블이 가지고 있는 열은 여러가지가 있지만, 그 중에서도 눈여겨볼만한 지표는 아래와 같다.
| Instrument Class | Description | Importance |
| CREATED_TMP_DISK_TABLES | 디스크 기반의 임시 테이블을 생성한 횟수 지표. 쿼리를 최적화하거나 임시 테이블의 최대 크기를 늘려서 해결 가능. | ⭐⭐⭐ |
| SELECT_FULL_JOIN | 쿼리를 해결할 좋은 인덱스가 없어서, JOIN이 전체 테이블 스캔을 수행했다는 지표. 테이블이 아주 작지 않다면 인덱스를 재고해야함. | ⭐⭐⭐ |
| SELECT_RANGE_CHECK | JOIN에 사용할 인덱스가 없는 경우, 각 행 다음에 키가 있는지 확인. 이것은매우 나쁜 신호이며, 이 값이 0보다 클 경우 인덱스를 재고해야함. | ⭐⭐⭐ |
| SORT_SCAN | 정렬이 테이블을 스캔해서 조회한 경우. 의도적으로 인덱스를 사용하지 않고 테이블의 모든 행을 조회한 것이 아니라면 매우 나쁜 신호. | ⭐⭐⭐ |
| NO_GOOD_INDEX_USED | 쿼리를 수행하는 데 사용된 인덱스가 최적이 아닌 경우. 이 값이 0보다 크면 인덱스를 재고해야함. | ⭐⭐⭐ |
| NO_INDEX_USED | 쿼리를 수행하는데 인덱스가 사용되지 않은 경우. 테이블의 크기가 작으면 무시할 수 있지만, 클 경우 인덱스를 재고해야함. | ⭐⭐⭐ |
| CREATED_TMP_TABLES | 메모리 기반 임시 테이블을 생성한 횟수 지표. 메모리 임시 테이블을 사용하는 것 자체는 나쁘지 않음. 다만, 기본이 되는 테이블이 커지면 디스크 기반 테이블로 변환될 수 있고, 이를 예방하는 것이 중요. | ⭐⭐ |
| SELECT_FULL_RANGE_JOIN | JOIN이 참조된 테이블의 범위 검색을 사용한 경우. | ⭐⭐ |
| SELECT_SCAN | JOIN이 첫 번째 테이블의 전체 스캔을 수행한 경우. 테이블이 클 경우 문제가 됨. | ⭐⭐ |
| SORT_ROWS | 정렬된 행의 수. 반환된 행의 수와 비교되며, 정렬된 행 수가 더 많으면 쿼리를 최적화해야함. | ⭐⭐ |
| SELECT_RANGE | JOIN이 첫 번째 테이블의 행을 확인하기 위해 범위 검색을 사용한 경우. | ⭐ |
| SORT_MERGE_PASSES | 정렬을 수행해야 하는 경우 병합을 수행하는 횟수. | ⭐ |
| SORT_RANGE | 범위를 사용하여 정렬을 수행한 경우. | ⭐ |
2. sys 스키마 사용
sys 스키마란?
버전 5.7 부터는 MySQL 내 sys 스키마라고 하는 performance_schema 데이터에 대한 동반 스키마가 포함되어 있다.이 스키마는 performance_schema에 대한 뷰와 스토어드 루틴만으로 구성되어 있다. performance_schema를 보다 손쉽게 사용하도록 설계되었지만, 자체적으로 데이터를 저장하지는 않는다.
sys 스키마를 이용해서 문제가 있는 구문을 찾을 수도 있다. 가령, statements_with_errors_or_warnings는 오류와 경고를 반환한 모든 구문을 나열하고, statements_with_full_table_scans는 전체 테이블 스캔이 필요한 모든 구문을 나열한다. 아래는 sys 스키마를 사용한 예시이다.
SELECT query, total_latency, no_index_used_count, rows_sent, rows_examined
FROM sys.statements_with_full_table_scans
WHERE db = 'user' AND query NOT LIKE '%performance_schema%';아래는 위 쿼리에서 db 조건절을 지우고, 로컬에서 실행한 결과이다. ( 오래된 로컬 데이터베이스라 기록이 없다 )

메모리 사용량 점검
performance_schema에서 메모리 계측을 활성화하려면 클래스 memory의 인스트루먼트를 활성화하면 된다.
1. Performance schema 직접 사용
성능 스키마는 이름이 memory_summary_ 접두사로 시작하는 다이제스트 테이블에 메모리 사용 통계를 저장한다. 메모리 사용 집계는 다음과 같다.
| 집계 파라미터 | 설명 |
| global | 이벤트명당 전역으로 |
| thread | 스레드당 ( 백그라운드 스레드와 사용자 스레드 모두 포함 ) |
| account | 사용자 계정 |
| host | 호스트 |
| user | 사용자명 |
2. sys 스키마 사용
sys 스키마는 host, user, thread, global에 의한 집계를 지원한다. sys 스키마 내 메모리 통계 뷰 중 memory_global_total 뷰는 메모리의 총량을 표시해준다. 집계 뷰는 필요에 따라 바이트를 킬로바이트, 메가바이트, 기가바이트로 변환한다.
SELECT * FROM sys.memory_global_total;
memory_by_thread_by_bytes 뷰의 행은 현재 할당된 메모리를 기준으로 내림차순으로 정렬되기 때문에 대부분의 메모리를 사용하는 스레드를 쉽게 찾을 수 있다.
SELECT thread_id tid, user, current_allocated ca, total_allocated
FROM sys.memory_by_thread_by_current_bytes
LIMIT 9;
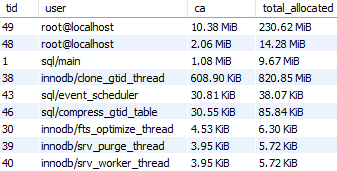
결과에서도 볼 수 있듯이, 로컬 연결이 대부분의 메모리를 사용하고 메인 서버 프로세스가 다음으로 많은 메모리를 사용하는 것을 볼 수 있다. 결괏값은 실제 운영되는 라이브 서버의 데이터베이스 내 결과와는 다를 수도 있다. 다만, 이를 이용해서 가장 메모리를 많이 사용하는 사용자 스레드를 쉽게 찾을 수 있다.
변수 점검
MySQL에는 크게 두 가지 변수 타입이 있다.
1. 전역 변수: global_variables 테이블에 저장된다.
2. 세션 변수: session_variables 테이블에 저장된다.
global_variables 테이블과 session_variables 테이블 모두 VARIABLE_NAME 및 VARIABLE_VALUE 두 가지 열을 갖고 있다. 한편, varaibles_by_thread 테이블에는 변수가 속한 스레드를 나타내는 열인 THREAD_ID 가 추가적으로 존재한다. 이를 통해 세션 변수 값이 스레드마다 어떻게 다르게 설정되었는지 확인이 가능하다.
사용 예제 1) 스레드별 트랜잭션 수준 조회
SELECT * FROM performance_schema.variables_by_thread WHERE VARIABLE_NAME='transaction_isolation';
만약 특정 스레드에서 해당 변수가 SERIALIZABLE로 설정되어 있다면, 다른 기본 수준의 트랜잭션들보다 잠금을 더 많이 유발한다고 인지할 수 있다.
사용 예제 2) 현재 활성화된 세션과 다른 세션 변수 값을 가지는 모든 스레드 조회
SELECT vt2.THREAD_ID AS TID, vt2.VARIABLE_NAME, vt1.VARIABLE_VALUE AS MY_VALUE, vt2.VARIABLE_VALUE AS OTHER_VALUE
FROM performance_schema.variables_by_thread vt1
JOIN performance_schema.threads t USING(THREAD_ID)
JOIN performance_schema.variables_by_thread vt2 USING(VARIABLE_NAME)
WHERE vt1.VARIABLE_VALUE != vt2.VARIABLE_VALUE AND t.PROCESSLIST_ID=@@pseudo_thread_id;
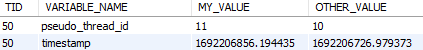
사용 예제 3) 어떤 연결이 서버에서 가장 많은 리소스를 사용하는지 식별하기
SELECT * FROM performance_schema.status_by_thread WHERE VARIABLE_NAME='Handler_write';

상태 변수는 사용자 계정, 호스트, 사용자 그리고 스레드별로 집계가 가능하다. 저자는 그 중에서도 스레드별 집계에 흥미를 갖는데, 이를 통해 어떤 연결이 서버에서 가장 리소스를 많이 사용하는지 식별 가능하기 때문이다. 가령, 위와 같은 쿼리 결과에서 우리는 THREAD_ID=51 이 대부분의 쓰기 작업을 수행하고 있음을 알 수 있다.
자주 발생하는 오류 점검
performance_schema는 사용자, 호스트, 계정, 스레드 및 전역 오류 번호 별로 오류를 집계하는 다이제스트 테이블을 제공한다.
사용 예제) 오류를 10번 이상 발생시킨 구문을 실행한 모든 계정 조회
SELECT *
FROM performance_schema.events_errors_summary_by_account_by_error
WHERE SUM_ERROR_RAISED > 10 AND USER IS NOT NULL
ORDER BY SUM_ERROR_RAISED DESC;
- ERROR_NUMBER, ERROR_NAME, SQL_STATE는 오류를 식별한다.
- SUM_ERROR_RAISED는 오류가 발생한 횟수이다.
- SUM_ERROR_HANDLED는 오류가 처리된 횟수이다.
- FIRST_SEEN과 LAST_SEEN은 오류가 처음과 마지막으로 발생한 타임스탬프이다.
위와 같은 오류 다이제스트 테이블을 통해 가장 잘못된 쿼리를 전송하고 그 작업을 수행한 사용자 계정, 호스트 사용자, 스레드를 쉽게 찾을 수 있다.
'Database > High Performance MySQL' 카테고리의 다른 글
| 서버 설정 최적화 (0) | 2023.09.10 |
|---|---|
| 운영 체제 및 하드웨어 최적화 (0) | 2023.08.26 |
| Performance Schema (1) (0) | 2023.08.15 |
| 신뢰성 엔지니어링 환경에서의 모니터링 (2) | 2023.07.31 |
| MySQL 아키텍처 (0) | 2023.07.23 |