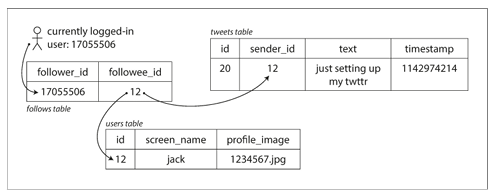
트랜잭션 처리와 분산 일반적인 온라인 어플리케이션에서는 여러 종류의 데이터가 사용자 입력을 기반으로 삽입되거나 갱신된다. 이는 클라이언트와 서버 간의 대화식이기에, 이 접근 패턴을 온라인 트랜잭션 처리( online transaction processing, OLTP )라고 한다. OLTP는 이익을 산출하는 비즈니스에 맞닿아 있기에 대부분의 데이터 베이스는 OLTP 에 맞추어 설계되고 발전되었다. 하지만 시간이 지남에 따라 사람들은 데이터 베이스를 "데이터 분석 ( data analytic )" 목적으로도 많이 사용하기 시작했다. 데이터 분석은 기존 트랜잭션과 접근 패턴이 매우 다르다. 분석에 사용되는 쿼리는 사용자에게 원시 데이터만을 반환하지 않고, 많은 수의 레코드에 대한 집계 통계를 계산해야 했기..